
Modelling a chase is hard. I was looking for a rule of thumb: a quick calculation that could support the monte-carlo simulation I run. And here it is:
Decimal odds of chasing team winning = 1 + (Required Runs/Expected Runs)^8
Jonas (@cric_analytics)
Jonas gave the example of Australia needing 145 more to win an ODI against England. He thought Australia could on average expect to score 110 from their last 20 overs. Australia’s decimal odds were thus 1+(145/110)^8 = 10.1 (or roughly a 10% chance of winning).
To successfully unpack (or steal!) the formula, the element that needs a bit of thought is “Expected Runs”. We can use Duckworth-Lewis, combined with ground data to give an approximation. 20 overs & 5 wickets left meant 38.6% of resources remaining. On a 285 par pitch, that’s the 110 Expected Runs that Jonas calculated.
Taking the formula one step further, “Expected Runs” can be adjusted for the quality of the batting and bowling teams to give a more precise calculation for a specific run chase. I have added this expanded formula to my model to better understand who is winning and why.
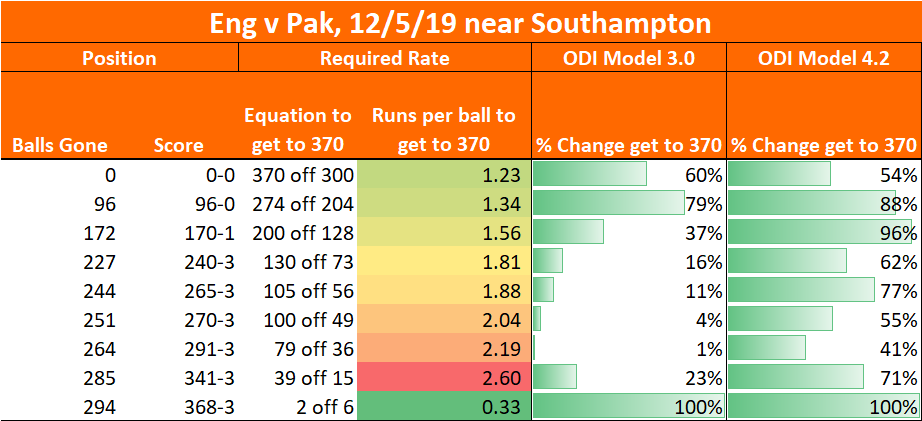
Here’s an example of what this looked like when Australia were 222-5, needing another 81 from the last 10 overs (third ODI, 16th Sept 2020):
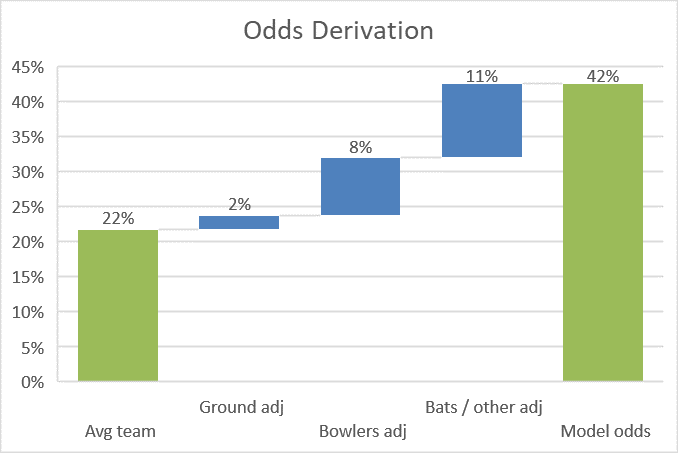
The raw formula gave Australia a 22% chance with 26.1% of resources remaining (Expected Runs = 69, on the basis that a normal par score is 264 – that may be an underestimate as scores keep rising). However Old Trafford slightly favours the batsmen, and England’s attack is sub par – lifting Australia to 32%.
My model had Australia at a 42% chance – the extra 10% coming from the strength of Australian batting, the two batsmen being set, and any other differences between my model’s Monte Carlo simulation and Jonas’ formula. The right hand column is the output of my model, and the penultimate column is the one that goes haywire if something is wrong: a useful check.
What’s the message? Firstly, if the model is working, I can see who is winning during a chase and why. Secondly, matchups and other complexity have made my model something of a “black box” – Jonas’ formula will be a useful check that my model isn’t off piste.

_method_of_adjusting_target_scores.PNG#/media/File:(Duckworth_Lewis)_method_of_adjusting_target_scores.PNG){kind=link}