
Averages are the currency of red ball cricket. We know they get misused (eg. after just a handful of games Ben Foakes averages 41) and when abused they have little predictive power. What I hadn’t realised is just how limited averages are: we almost never have a satisfactory sample size for someone’s average to be the definitive measure of their ability.
Number of innings before you can rely on an average
We can all agree that averages after a couple of innings are of very little value. By “value” I mean predictive power: what does it tell you about what will happen next?
Ben Foakes averaging 42 after five Tests doesn’t mean a lot. But how about Keaton Jennings averaging 25 after 17 Tests?
The below charts show the limitations of averages by comparing them after 10/20/30 Tests (x-axis) with those players’ averages for the rest of their careers (y-axis). The sample is players since 2000 who played more than 70 Tests.
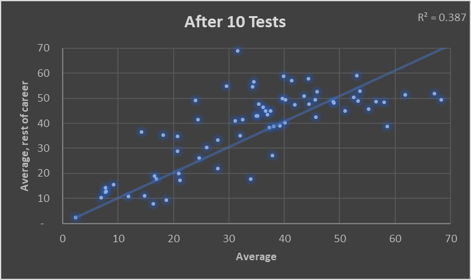
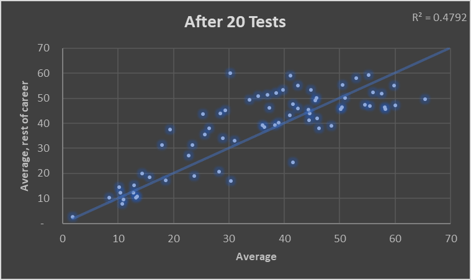
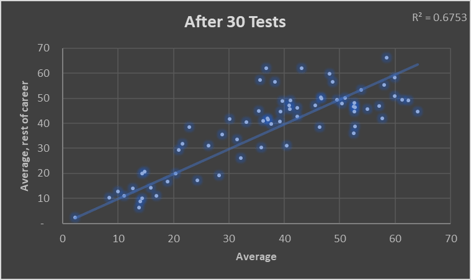
It’s quite striking how dispersed the data is. Not just the 10 Test version (Stuart Broad averaged more than Steve Smith), but even over a longer horizon: Michael Vaughan averaged 53 in his first 30 Tests of this century, then 36 in his last 50 Tests (32% less).
Modelling and True Averages
Sports models are often positively described as “simulating the game 10,000 times”. This isn’t just to make the model sound authoritative, it can take that many simulations to get an answer not influenced by the laws of chance. When I look at an innings in-running, balancing speed against accuracy, I’ll run at least a thousand simulations – any fewer and the sample size will impact results. An example from today – Asad Shafiq’s expected first innings average was 55, yet a 1,000 iteration run of the model gave his average as 54.3. Close, but not perfect.
Shouldn’t it be the same with averages? If we don’t have a thousand innings, lady luck will have played a part. We never have a thousand innings.
Looking at modelled data, I find that after 35 innings (c. 20 Tests), there is still a one-in-five chance that someone’s average differs by more than 20% from what they would average in the long term. A batsman that would average 40 in the long run could, through bad luck, average 32 after 20 Tests.
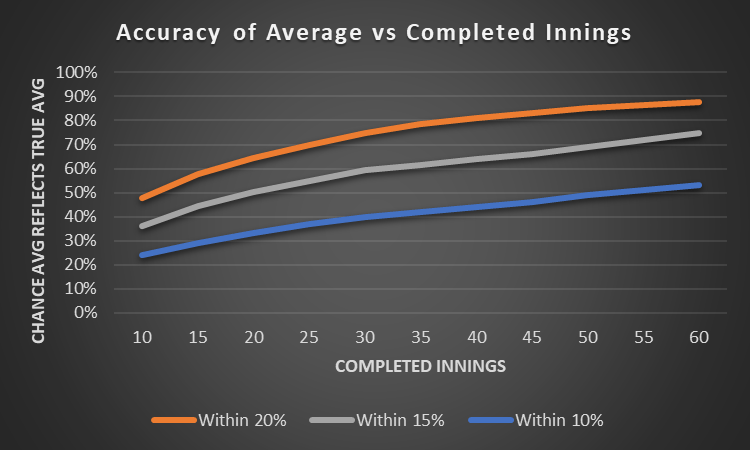
Sir Donald Bradman had a 99.94 average at the end of his career (70 completed innings). There’s a c.40% chance his average would have been +/- 10% if he had played enough innings for his average to have been a true reflection of his ability. We don’t know how good Bradman was*.
Implications
- Don’t blindly slice & dice averages – they’ll tell you a story that isn’t true. Yes, if you have a mechanism to test (eg. Ross Taylor before and after eye surgery), there might be a real story. But just picking a random cutoff will mean you misread noise as signal (Virat Kohli averaged 44 up to Sept 2016, but 70 since then).
- Use age adjusted career averages as a best view of future performance.
- First Class data has to be a factor in judging Test batsmen, even when they have played 30 Tests. Kane Williamson averaged just 30 in his first 20 Tests. Credit to the New Zealand selectors for persevering.
- There has to be a better metric than batting average. Times dismissed vs Expected Wickets times (Strike Rate / Mean Strike Rate) is one that I’d expect to become commonplace in future. Another might be control % in the nets. Yes, I went there: I believe there is some merit in the “he’s hitting it nicely in the nets” line of reasoning.
This analysis can be repeated for 20-20 – I’ll cover that in my next post.
Further reading
Owen Benton already covered the modelled side of averages here. His found an 80% chance that a batsman’s average is within 20% of their true average after 50 innings, which is in line with my modelling. His approach is rather practical: what’s the chance an inferior batsman has the better average after x innings?
*Factor in Bradman’s 295 completed First Class innings at an average of 95 and we can get precision on how good he was. But that sentence would lack punch, and this blog’s barely readable at the best of times.

One thought on “On the limitations of averages”