
A batting average is a record of what a player has achieved. The fewer matches played, the less meaningful that average. I propose an approach to estimate the range of possible long term averages a player might have, based on their current average plus the number of innings played. I’ll talk about Mark Ramprakash too, just to keep things fun.
Imagine a new batsman on the scene. Assume we magically know they have the technique to average exactly 30. By using a Monte Carlo simulation, we can see the paths their average might take by chance.*
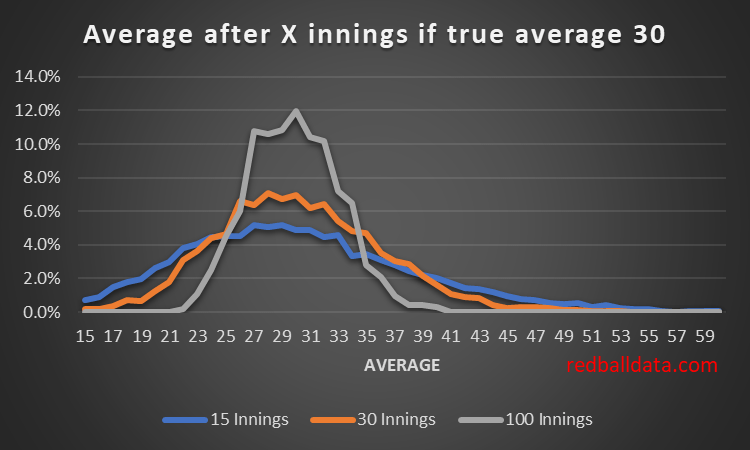
By embracing the uncertainty in averages we can better interpret them. Using the simulated data, we can estimate the uncertainty (standard deviation) of a player’s average once they have played a given number of games.**
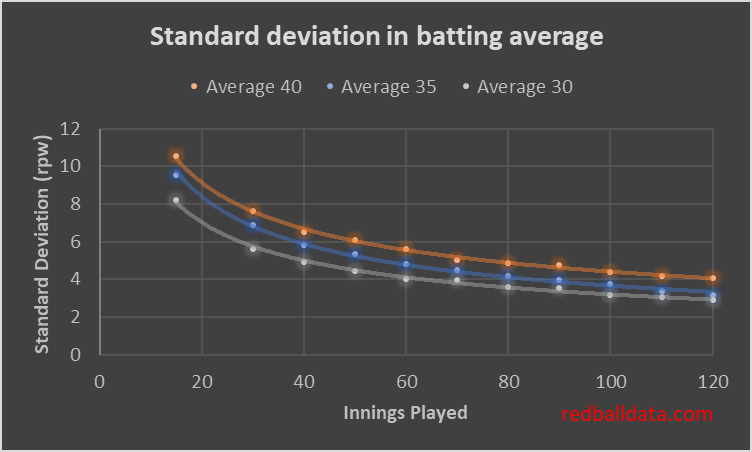
A standard deviation of 10 means a 95% chance the true average is within 20 runs of the observed average. That’s where we are for a top order batsman after 15 innings: it’s too early to use the data to conclude, though qualitative judgements on technique are possible.
There are four practical uses for this analysis:
1. Identifying players out of their depth
Mark Ramprakash averaged 53 in First Class but only half as much in Tests. We can now quantify how likely it is that he wasn’t going to cut it as a Test batsman: and thus propose an approach for when players should be dropped.
Ramprakash’s career: 671 dismissals in First Class means a negligible level of uncertainty in his FC abilities (albeit we could fit an age curve to this for a better estimate of his peak talent). 86 Test dismissals averaging 27.3 (that takes me back to the 1990s).
Let’s assume Tests were about 20% harder than 1990s First Class cricket. Ramps’ theoretical Test average would be 53 * 0.8 = 42.4. Now for the distribution of averages for a batsman with that skill level playing 86 innings:
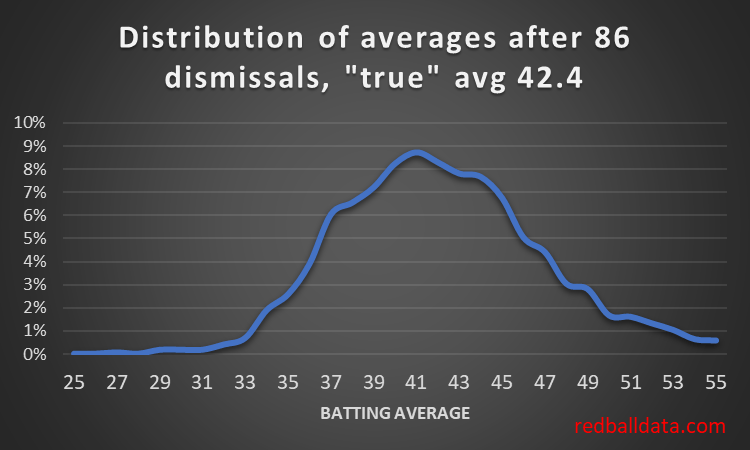
Figure 3 tells us it’s almost certain Ramprakash wasn’t the same player in Tests.
But when should he have been dropped? He got a lot of chances. Assume the weakest specialist batsman averages 35. A player should be dropped when they are underperforming the reasonable range of scores that a batsman averaging 35 would produce.
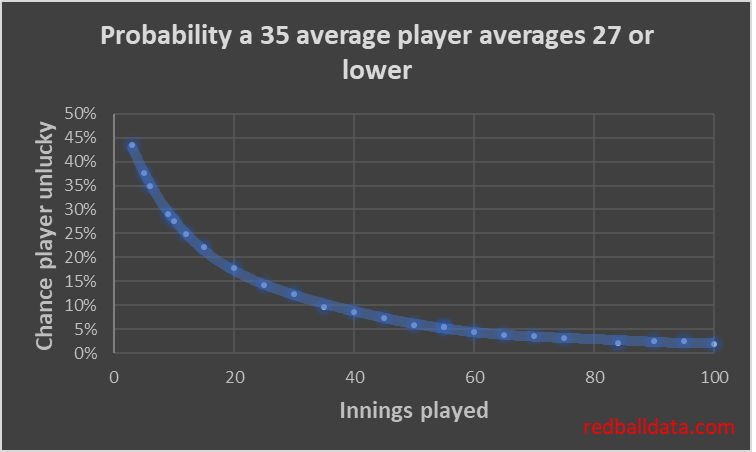
We can see that after 86 dismissals there was a less than 2% chance Ramprakash was capable of averaging 35 in Tests***. Personally, once a player is down to a 15% chance of just having been unlucky, I’d be looking to drop them. That’s 25 innings averaging 27 or under. There’s some evidence that England are already thinking along these lines. Jennings got 31 Test innings, (averaging 25), Denly 26 (30), Compton 27 (29), Malan 26 (28), Hales 21 (27), Vince 22 (25), Stoneman 19 (28). Note that a stronger county or 50 over record should get a player more caps- as it increases the chance that early Test struggles were bad luck (after 30 Test innings Kallis averaged 29, he ended up averaging 55).
I’m intrigued by the possibilities this method presents – I’ll follow up at a later date by looking at promising 2nd XI players who have struggled in County Cricket, and assessing whether they deserve another shot, or they’ve probably had their chips.
2. Adding error bars to averages
Remember here where I analyzed county players by expected D1 average? I now have the tools to add error bars to those ratings. Back in September I rated Pope above Root. What I wasn’t able to do at that time was reflect the uncertainty in Pope’s ranking because he only had 42 completed innings. Will cover that in a future blog post (with two small children at home, it’s surprisingly difficult to find time for analysis). Spoiler alert – after that many innings, we can say Pope’s expected Division 1 average was 61 (+/-14).
3. Modelling
I can use the uncertainty in Pope’s rating when modelling match performance. Something like for each innings assigning him an expected average based on the distribution of possible averages he might end up with in the long term. That uncertainty will be one of the inputs in my next Test match model (along with Matchups, realistic bowling changes, impact of ball age).
There will be greater uncertainty in a player’s rating when they have just stepped up or down a level.
4. Matchups
We can move from the limited “Jones averages 31 against left handers” to the precise “Jones averages 31 +/- 12 against left handers”, just by taking into account the number of dismissals involved. The cricketing world can banish the cherry pickers and charlatans with this simple change, where stats come with error bars.
***
There’s plenty to chew on here. I’ve not found any similar analysis of cricket before – kindly drop me a line and tell me what you think.
* A bit more detail – my model assumes a geometric distribution of innings-by-innings scoring. With that, one can assign probabilities of all possible outcomes to each ball, then simulate an innings ball-by-ball. To see the spread of outcomes after 100 innings, I ran the simulation 150,000 times, then grouped scores into 1,500 batches of 100 innings. Previous discussion about the limitations of using the first 30 innings as a guide to future performance is here.
** This isn’t perfect. This method estimates the range of observed averages from a given level of ability. In the real world it’s the other way around. That’s a more complicated calculation.
*** Actually slightly better than 2%, because his first class record was so strong (114 hundreds). Ramprakash was an unusual case: there was an argument for him playing far fewer Tests, and an equally good one for him to have been managed better and picked more consistently. I did a twitter poll which was split down the middle on these two choices. Nobody thought stopping slightly earlier would have been the right choice.

2 thoughts on “Adding error bars to averages”